
추천시스템에서 Candidate generation은 첫번째 스테이지 이다. 쿼리가 주어지면 시스템은 relevant candidates을 생성한다. 다음 표는 두 가지 일반적인 후보 생성 방법을 보여준다.
| 종류 | 정의 | 예제 |
|---|---|---|
| Content-based Filtering | items의 사이에 similarity를 상요해서 유저가 좋아하는 item과 유사한 항목을 추천 | 만약 사용자 A가 cute cat videos를 좋아하면 사용자에게 cute animal vidoes를 추천 |
| Collaborative Filtering | quries와 items의 사이의 similarity를 동시에 사용해 추천을 제공 | 사용자 A와 사용자 B가 유사하고, 사용자 B가 video 1을 좋아한다면, 사용자 A에게 video 1을 추천 |
Embedding Space
content-based와 collaborative filtering 은 모두 각 item과 각 query(또는 context)를 공통 임베딩 공간의 임베딩 벡터에 맵핑한다. embedding space는 low-dimensional (d, corpus 사이즈보다 작은), item또는 query 셋의 latent structure를 캡쳐한다. 유사한 items은 보통 같은 유저에 의해 시청된다. 임베딩 공간에서 서로 가깝게 위치합니다. 가깝다(closeness)는 similarity measure로 정의된다.
Similarity Measures
similarity measure는 함수로 두개의 embeddings의 쌍이 주어지면 두개의 임베딩 사이의 similarity를 스칼라의 값으로 반환하는 역할을 한다. embeddings은 candidate generation에서 다음과 같이 사용: query embedding이 주어지면 system은 q와 가까운 item embeddings에서 가까운 item embedding x를 찾는다. 두개의 임베딩은 s(q,x) - high similarity
degree of similarity를 결정하기 위해서, 대부분의 recommendation systems에서는 아래에서 하나 이상에 의존:
- cosine
- dot product
- euclidean distance
Which Similarity Measure to Choose?
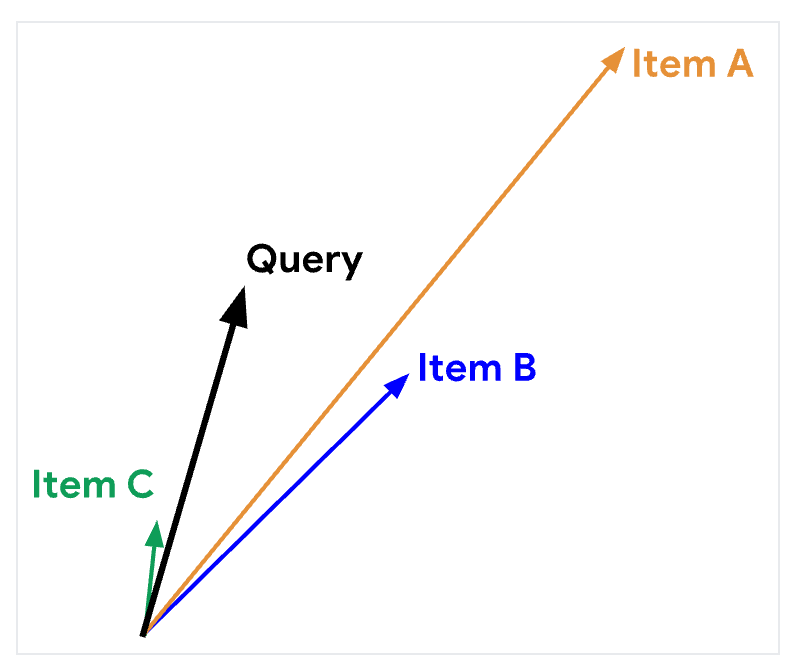
- 그림설명
- Item A의 경우 largest norm,
- Query와 Item C는 cosine했을때 각이 작아서 가장 유사하게
- Query와 Item A는 largest norm이기 때문에 Dot product했을때 가장 유사하게
- Query와 Item B는 Euclidean distance할때 가장 유사하게
- cosine과 비교했을때 dot product similarity는 embedding의 표준에 sensitive
- embedding의 norm이 클수록, 더 큰 similarity (for items with an acute angle)와 항목이 추천될 가능성이 높다.
- training set에 빈번하게 등장하는 아이템(인기있는 비디오)는 large norms의 임베딩을 갖을 경향이 크다. 인기 정보를 캡처하는것이 바람직하다면 dot product를 선호해야 한다. 그러나 주의하지 않으면 인기 상품이 추천 항목을 압도할 수 있다. 실제로 item의 표준을 덜 강조하는 similarity measures의 다른 변형을 사용할 수 있다. 예를들면 아래와 같이
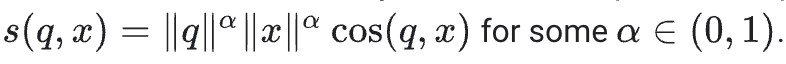
- 매우 드물게 나타나는 item은 훈련 중에 자주 업데이트 되지 않을 수 있다. 만약 큰 표준화로 초기화가 되면, 시스템은 rare items을 관련성이 높은 항목보다 추천할 수 있다. 이 문제를 피하기 위해서는 embedding initialization을 주의하고, 적절하게 정규화를 사용해야 한다. 이 문제는 첫번째 연습에서 자세하게 설명한다.
참고
- https://developers.google.com/machine-learning/recommendation/overview/candidate-generation