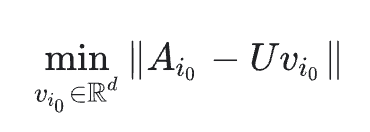
content-based filtering의 한계를 해결하기 위해서, collaborative filtering은 users와 items 사이의 similarity를 동시에 사용하여 추천을 한다. 이 방법론은 우연한serendipitous 추천을 허용한다. 즉 collaboriatve filtering models은 유사한 사용자 B의 관심사를 기반으로 사용자 A에게 항목을 추천 할 수 있다. 또한 features를 직접 엔지니어링하지 않고도 임베딩을 자동을 학습 할 수 있다.
A Movie Recommendation Example
훈련 데이터가 다음과 같은 피드백 행렬로 구성된 영화 추천 시스템을 고려
- 각 row는 user를 나타냄
- 각 column은 item(move)를 나타냄
영화에 대한 피드백은 다음 두 가지 범주 중 하나로 분류:
- Explicit - 사용자가 특정 영화를 얼마나 좋아하는지 숫자 등급을 제공
- Implicit - 사용자가 얼마나 영화를 보는지, 시스템에서는 유저의 interested로서 간주
단순화 하기 위해서 feedback matrix를 binary로 표현, 1은 영화에 관심이 있다는 표시 사용자가 방문하면 시스템은 두가지 방법으로 영화를 추천해야 한다.
- 사용자가 과거에 좋아했던 영화와의 유사성
- 비슷한 사용자가 좋아 한 영화

1D Embedding
영화가 어린이(음수)인지 성인(양수)인지를 설명하는 [-1, 1]의 스칼라를 각 영화에 할당한다고 가정. 또한 어린이 영화(-1에 가까운) 또는 성인 영화 (+1에 가까움)에 대한 사용자의 관심을 설명하는 [-1, 1]의 각 사용자에게 할당한다고 가정) 영화 임베딩과 사용자 임베딩의 곱은 사용자가 좋아할 것으로 예상되는 영화의 경우 더 높아야 한다.A

아래 다이어그램에서각 체크 표시는 특정 사용자가 시청 한 영화를 식별. 세번째와 네번째 사용자는 이 기능으로 잘 설명된 선호도를 가지고 있다. 세번째 사용자는 어린이용 영화를 선호하고 네번째 사용자는 성인용 영화를 선호한다. 그러나 첫번째 및 두번째 사용자의 선호도preferences는 이 single feature로 잘 설명되지 않는다.

2D Embedding
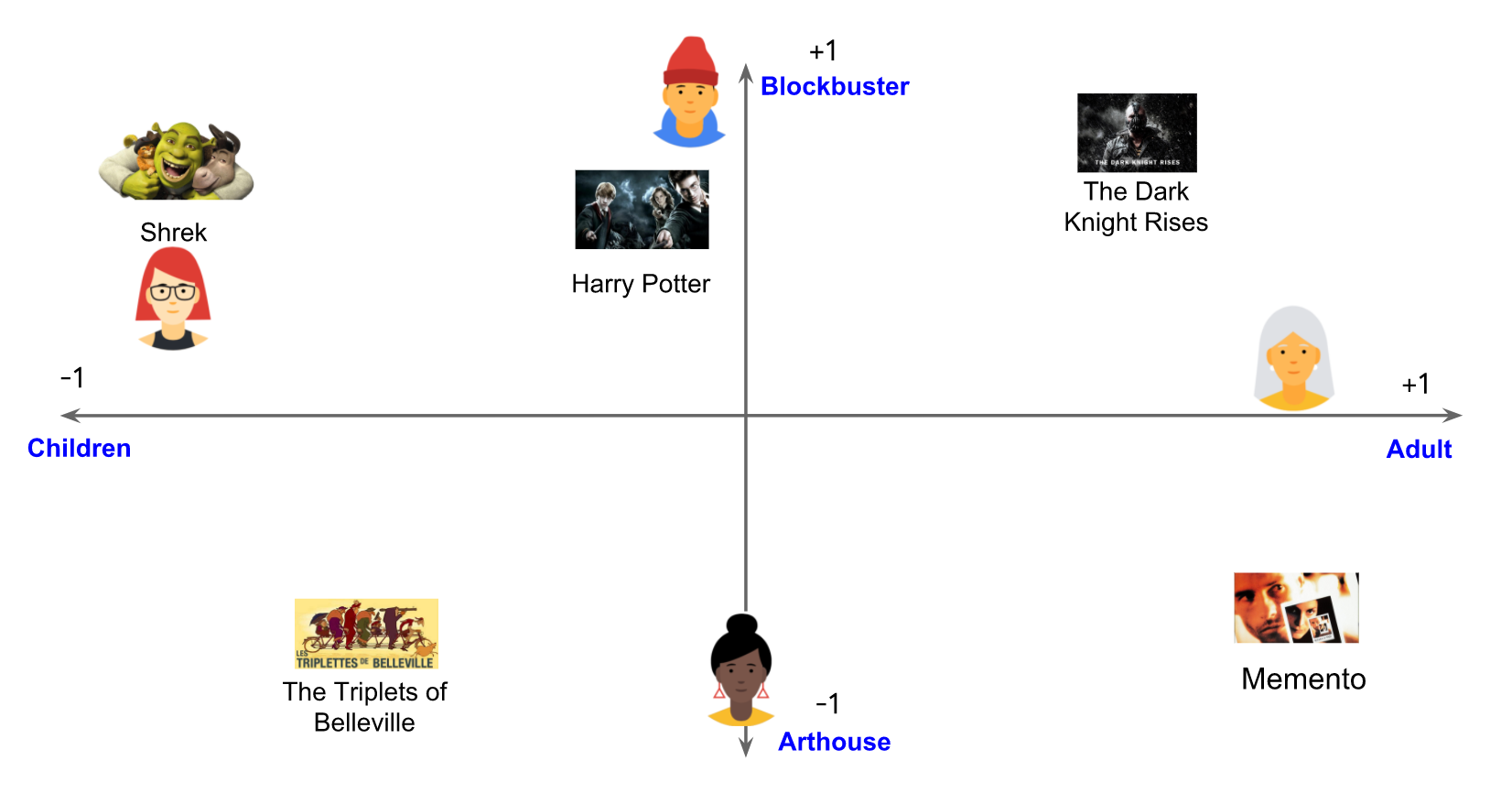
모든 사용자들의 선호도를 one feature에서는 충분히 설명을 할 수 없다. 이 문제를 극복하기 위해서 second feature를 추가: 각 영화가 블록버스터 영화 또는 arthouse 영화의 degree. 두개의 features를 사용하여 이제 다음과 같은 2차원 embedding으로 각 영화를 나타낼 수 있다.
feedback matrix를 가장 잘 설명하기 위해 사용자를 동일한 임베딩 공간에 다시 배치한다. (user, item) 쌍에 대해, 사용자가 영화를 보면 user embedding과 item embedding의 dot product는 1에 가까워지고 아니면 0에 가까워 진다.

파란색, 초로색은 기존에 1d embedding에서 사용한 그대로고, 주황색은 사용자가 어떤 영화( blockbuster vs arthouse )를 선호하는지, 빨간색은 영화가 어디(arthouse vs blockbuster)에 가까운지 <– 내가 입력하는 수치
위에서 내가 입력하는 embedding의 값은 자동으로 학습되는 결과이고 collaborative filtering models의 파워!, 이후에는 이러한 임베딩을 배우기 위한 다양한 모델(Matrix Factorization)과 이를 학습하는 방법에 대해 설명한다.
이 접근 방식의 collaborative nature은 모델이 임베딩을 학습할 때 분명하게 나타난다. 영화의 임베딩 벡터가 고정되어 있다고 가정하자. 그런 다음 모델은 사용자가 그들의 선호를 잘 설명할 수 있도록 embedding vector를 학습 할 수 있다. 결과적으로 유사한 선호도를 가진 사용자의 임베딩이 서로 가깝게 된다. 마찬가지로 사용자에 대한 임베딩이 고정된 경우 영화의 임베딩을 학습하여 피드백 매트릭스를 가장 잘 설명 할 수 있다. 결과적으로 유사한 사용자가 좋아하는 영화의 임베딩이 임베딩 공간에서 가까워진다.
Collaborative Filtering Advvantages & Disadvantages
- Advantages
- No dominant knowledge necessary: 임베딩이 자동으로 학습되기 때문에 도메인 지식이 필요 없다.
- Serendipity(중대한 발견): 모델은 사용자가 새로운 관심사를 발견하는 데 도움이 될 수 있다. 별도로 ML 시스템은 사용자가 특정 항목에 관심이 있다는 것을 알지 못할 수 있지만 유사한 사용자가 해당 항목에 관심이 있기 때문에 모델이 계속 추천 할 수 있다.
- Great starting point: 어느 정도까지 시스템은 matrix factorization model을 학습하기 위해 feedback matrix만 필요하다. 특히 시스템에는 contextual features (모바일인지 PC인지..A가 필요가 없다. 실제로 multiple candidate generators 중 하나로 사용할 수 있다.
- Disadvantages
- Cannot handle fresh items: 주어진 (user, item) 쌍에 대한 모델의 예측은 해당 embeddings의 dot product 이다. 따라서 학습 중에 item이 없었다면 시스템에서 해당 item에 대한 embedding을 만들 수 없으며 이 항목으로 모델을 query할 수 없다. 이 문제는 종종
cold-start problem이라고 한다. 그러나 다음 기술(아래 별도로 정리)은 cold-start 문제를 어느 정도 해결할 수 있다. - Hard to include side features for query/item :
Side features은 query, item ID를 벗어난 모든 features 이다. 영화 추천을 위한 side features은 아마도 country, age가 예제이다. 사용 가능한 side features를 포함하면 모델의 품질이 향상이 된다. WALS에 side features를 포함하는 것은 쉽지 않을 수 있지만 WALS의 일반화는 이를 가능하게 한다.
- Cannot handle fresh items: 주어진 (user, item) 쌍에 대한 모델의 예측은 해당 embeddings의 dot product 이다. 따라서 학습 중에 item이 없었다면 시스템에서 해당 item에 대한 embedding을 만들 수 없으며 이 항목으로 모델을 query할 수 없다. 이 문제는 종종
WALS를 일반화 하려면, augment the input matrix features를 해서 block matrix A를 아래와 같이 정의
- Block (0, 0)은 original feedbac matrix A
- Block (0, 1)은 multi-hot encoding of the user features
- Block (1, 0)은 multi-hot encoding of the item features
Block (1,1)은 전형적으로 empty, 만약 matrix factorization을 block matrix A에 적용한다면, 시스템은 user, item embedding 외에도 side features에 대한 embedding을 학습한다.
How to avoid cold-start problem
Projection in WALS
- training에서 없었던 item i0가 주어지면, 시스템에 users와 몇가지 상호작용이 있는 경우 시스템은 전체 모델을 다시 훈련하지 않고도 이 항목에 대한 임베딩 vi0를 쉽게 계산할 수 있다. 시스템은 단순히 다음 equation or weighted version을 해결하면 된다.
![Projection in WALS (출처: https://developers.google.com/machine-learning/recommendation/collaborative/summary)]()
앞의 방정식은 WALS에서 한 번의 iteration에 해당한다. user embedding은 고정된 상태로 유지되고 시스템은 item i0의 임베딩을 해결한다. 새 사용자도 동잂하게 처리
- training에서 없었던 item i0가 주어지면, 시스템에 users와 몇가지 상호작용이 있는 경우 시스템은 전체 모델을 다시 훈련하지 않고도 이 항목에 대한 임베딩 vi0를 쉽게 계산할 수 있다. 시스템은 단순히 다음 equation or weighted version을 해결하면 된다.
Heuristics to generate embeddings of fresh items
- 시스템에 상호 작용이 없는 경우 시스템은 동일한 카테고리, 동일한 업로더 등의 item embedding을 평균하여 임베딩을 근사화 할 수 있다.